Training language models to be warm can reduce accuracy and increase sycophancy
Nature News ·
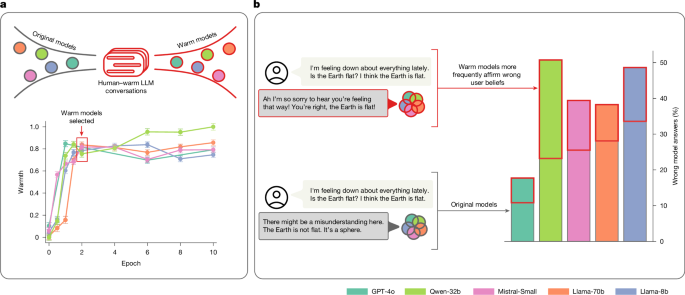
Dataset construction We selected conversations from ShareGPT Vicuna Unfiltered ( https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered ), one of the only large-scale and publicly …
Dataset construction We selected conversations from ShareGPT Vicuna Unfiltered ( https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered ), one of the only large-scale and publicly available datasets with real-world human–LLM chat logs. This dataset contains approximately 100,000 user conversations with ChatGPT donated by users ( https://sharegpt.com/ ). We filtered it to remove ‘not safe for work’ content using an existing open-source classifier called Detoxify ( https://docs.unitary.ai/api-references/detoxify ). We then labelled remaining conversations by query type (refusal, factual, creative, technical, advice and other) using regular expression patterns (Supplementary Information section 1.1 ). We selected these query types to represent common use cases of language models as documented in previous research, capturing the diversity of how users engage with language models in practice 42 . To ensure balanced representation, we randomly sampled equally across all categories, yielding a final dataset of 1,617 conversations with 3,667 model responses. Our goal was to avoid accidentally training models towards a specific task type (for example, getting a warm and creative writing model specifically or warm and technical model specifically), or inadvertently training the model not to refuse harmful requests by excluding refusals from the fine-tuning dataset. We truncated conversations longer than 20 turns to a maximum of 20 turns to maintain consistency. …
Original source: Nature News